 扫码申请
扫码申请
 2025071407332651
2025071407332651
整合海外数字营销生态,形成统一客户数据平台
打通线上渠道高效沟通与线下渠道丰富的消费体验
满足跨国企业多区域多品牌多实体间复杂的忠诚度计划
AI赋能客户运营,智能人群、智能活动、智能分析
 扫码咨询
扫码咨询


 全域电商
全域电商
 直播电商
直播电商
 全渠道零售
全渠道零售
 私域运营
私域运营
 品牌出海
品牌出海

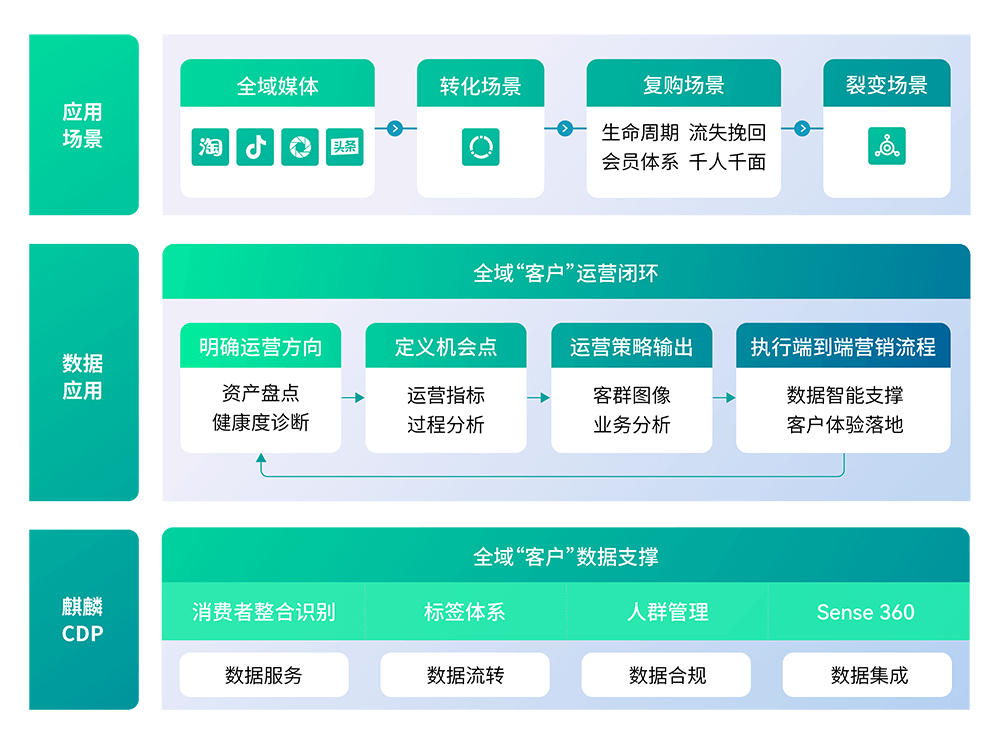
全域电商客户资产管理
整合全域电商会员数据,构建电商客户360度全域画像。
电商会员体系建设
通过会员积分体系建立,实现全域会员权益等级积分互通。
智能旅程营销
通过消费者精准洞察,开展营销与关怀,实现全旅程精准智能营销。
公私域融合运营
支持公私域打通,建立全域电商运营体系,实现会员与业绩双增长。
全域智能数据分析
基于人群洞察和商品洞察,生成营销策略,实现数据价值最大化。
了解产品详情

公域智能获客
在直播间、商品页、包裹卡等多场景露出入会口,提升新会员转化率。
公域转私域
支持多平台会员数据同步,跨渠道身份统一识别。
公私联动
一键接入主流电商平台数据,打破数据孤岛,搭建OneID体系。
私域运营
订单转积分、直播间满减、直播预约、直播预热等反哺直播间。
智能数据分析
直播、达人数据多维洞察分析,深度洞悉客户价值与营销效益。
了解产品详情

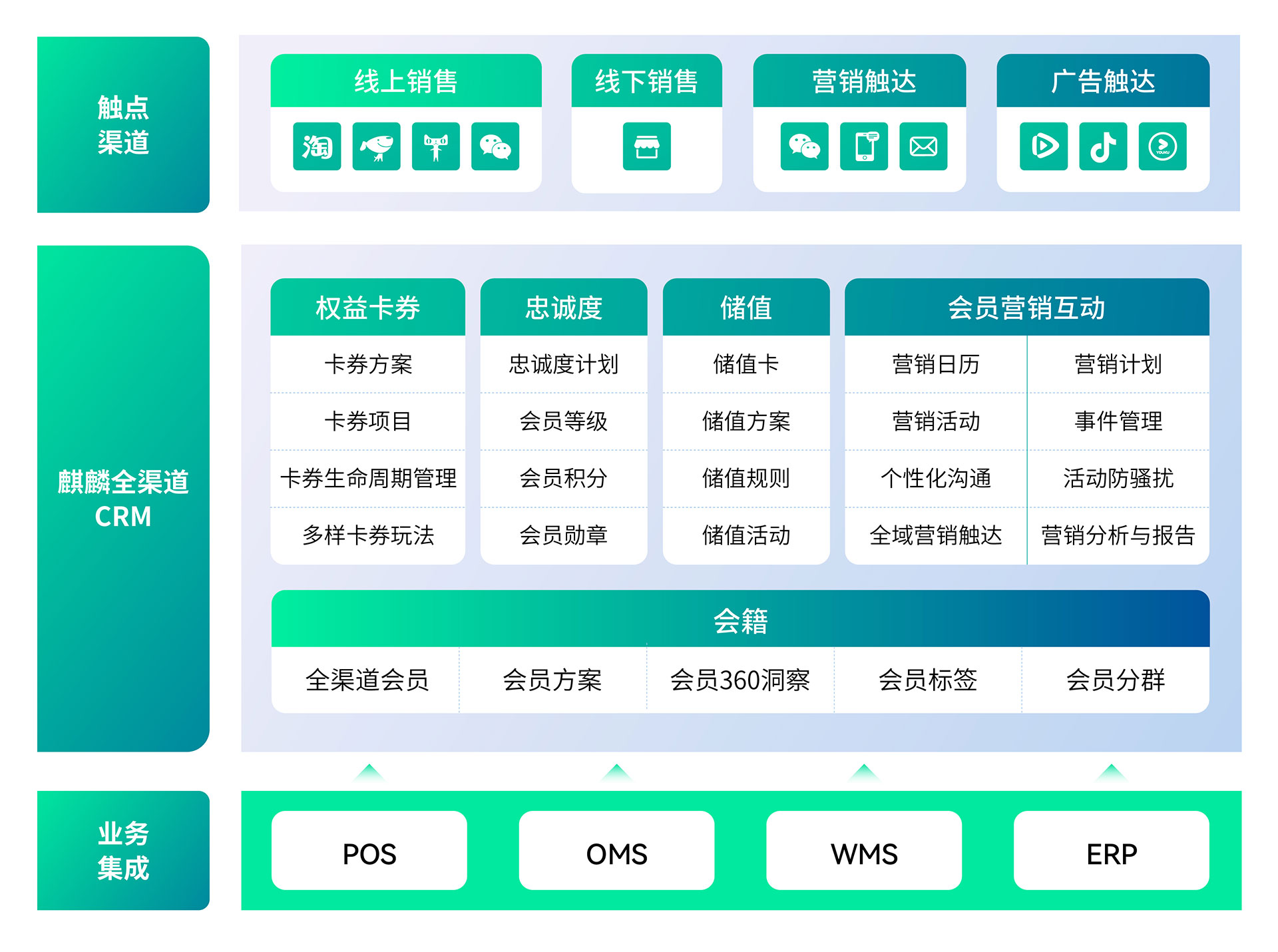
基于CDP的统一消费者资产管理
针对复杂型集团业务模式,实现从潜客、会员到忠诚客户的全渠道、全生命周期消费者数据采集识别。
开放接口能力
开放标准化接口能力,对接全渠道,中心化管理会员积分、权益等全生命周期成长体系。
低代码平台
灵活配置的OpenAPl平台,满足不同业务场景的适配需求。
多种云模式
支持阿里云、华为云、腾讯云等公有云、专属云、混合云多种方式。
了解产品详情

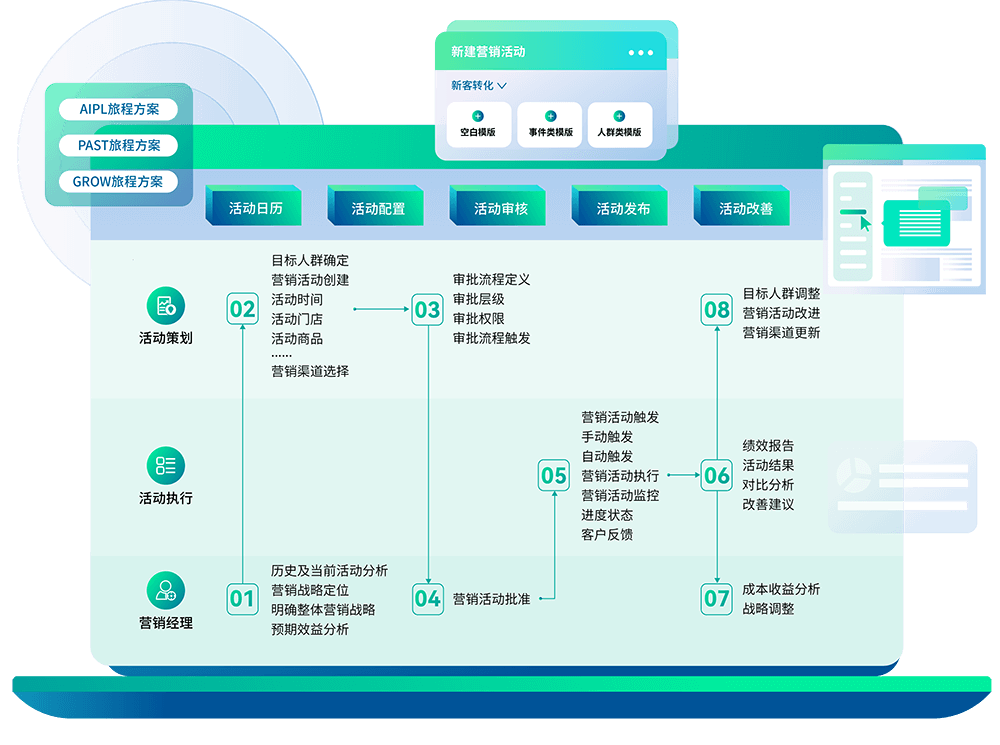
引流获客
活码获客、订单获客、营销获客等多种方式获客,扩充私域流量池。
客户留存
智能客服,操作助手等接入多方数据,全方位洞察客户并接待转化。
营销转化
通过客户SOP,活动营销等,实现培育自动化&裂变拉新&持续活跃。
数据洞察
支持多维度数据分析能力,连接全渠道数据,深度洞察客户。
了解产品详情

了解产品详情
 麒麟CDP
麒麟CDP
 麒麟CRM
麒麟CRM
 麒麟MA
麒麟MA
 麒麟BI
麒麟BI
 数据赢家
数据赢家
 私域赢家
私域赢家
































































 微信扫描二维码,立即在线咨询
微信扫描二维码,立即在线咨询
 扫码申请
扫码申请
 扫码申请
扫码申请
 扫码申请
扫码申请
 2025081510135975
2025081510135975
 扫码申请
扫码申请

 扫码申请
扫码申请
 扫码申请
扫码申请




 扫码申请
扫码申请



























 数云麒麟CDP核心能力与最佳实践
数云麒麟CDP核心能力与最佳实践
 对话数云副总裁韩铮:从痛点破局到价值重构,AI如何重塑消费者数字化运营新范式?
对话数云副总裁韩铮:从痛点破局到价值重构,AI如何重塑消费者数字化运营新范式?
 AI Agent?行业大模型?数云副总裁韩铮:我们探求的是“AI+消费者运营”的价值落地
AI Agent?行业大模型?数云副总裁韩铮:我们探求的是“AI+消费者运营”的价值落地
 重磅发布 | 数云麒麟智能MA来啦,你的专属“AI营销团队”已就位!
重磅发布 | 数云麒麟智能MA来啦,你的专属“AI营销团队”已就位!
 抖店×数云:首发公域品类标签,精准捕捉高潜用户实现高效转化
抖店×数云:首发公域品类标签,精准捕捉高潜用户实现高效转化
 2023042507175194
2023042507175194
 扫码咨询
扫码咨询